2015년 8월 13일 목요일
autoencoder 관련 정리
hidden layer 층, 노드 수 관련:
http://stackoverflow.com/questions/10565868/what-is-the-criteria-for-choosing-number-of-hidden-layers-and-nodes-in-hidden-la
http://stats.stackexchange.com/questions/101237/sparse-autoencoder-hyperparameters
phrase, sentence, document representation
Distributional Representations of Sentences and Documents (2014, Le and Mikolov)
- 단어 단위를 넘어 paragraph를 vector로 embedding
- 꼭 완성된 문장이 아니라도 추상화 가능하다는 것을 장점으로 내세움
- unsupervised
- Paragraph Vector with Distributed Memory (PV-DM)

- Paragraph Vector with Distributed Bag of Words (PV-DBOW)

- 실험방법: 영화 평가 문장 주어짐 -> word embedding ->phrase (sentence) vector 추출 (with gradient descent) -> logistic regression의 입력으로 이용, 영화 평점 예측
 - PV-DM 방법이 거의 성능에 영향, PV-DBOW는 보조적 역할
- PV-DM 방법이 거의 성능에 영향, PV-DBOW는 보조적 역할
- PV-DM에서 입력 vector의 합계보다는 concatenation 이용이 더 좋은 성능
From Word Embeddings To Document Distances (2015, Kusner, ICML)
- word embedding 결과가 주어진다는 가정 하에, 문서간 거리 측정 방법론 제시
- 논문에서 정의한 word mover's distance에 기반: 두 단어 vector간 거리를 distance로 이용
 - 거리 계산 복잡도를 낮출 수 있는 방법론도 같이 제시
- 거리 계산 복잡도를 낮출 수 있는 방법론도 같이 제시
- 문서를 직접 추상화하지는 않고 문서간 거리를 근거로 클러스터링 등 수행
- 단어 단위를 넘어 paragraph를 vector로 embedding
- 꼭 완성된 문장이 아니라도 추상화 가능하다는 것을 장점으로 내세움
- unsupervised
- Paragraph Vector with Distributed Memory (PV-DM)

- Paragraph Vector with Distributed Bag of Words (PV-DBOW)

- 실험방법: 영화 평가 문장 주어짐 -> word embedding ->phrase (sentence) vector 추출 (with gradient descent) -> logistic regression의 입력으로 이용, 영화 평점 예측

- PV-DM에서 입력 vector의 합계보다는 concatenation 이용이 더 좋은 성능
From Word Embeddings To Document Distances (2015, Kusner, ICML)
- word embedding 결과가 주어진다는 가정 하에, 문서간 거리 측정 방법론 제시
- 논문에서 정의한 word mover's distance에 기반: 두 단어 vector간 거리를 distance로 이용

- 문서를 직접 추상화하지는 않고 문서간 거리를 근거로 클러스터링 등 수행
2015년 8월 11일 화요일
word embedding 관련 정리
[language model]
A Neural Probabilistic Language Model (2003, Bengio)
- LM에 distributional representation을 적용한 대표 논문
- 계산복잡도 높음
Recurrent Neural Network based Language Model (2010, Mikolov)
Linguistic Regularities in Continuous Space Word Representations (2013, Mikolov)
- RNN을 이용한 LM
[word2vec]
Efficient Estimation of Word Representations in Vector Space (2013, Mikolov)
- word2vec 방법론 초기 논문
- 준수한 성능에 계산복잡도 감소
- CBOW, Skip-gram

-- hidden layer에서 non-linearity 제거
-- word간 projection layer 공유
- 대체적으로 semantic accuracy는 skip-gram이 낫고 syntactic accuracy는 cbow가 높은 것으로 보임
* 성능 수치 차이 및 전반적으로 봤을 때 skip-gram이 낫다고 보임 --> 이후 다른 논문들에서도 비슷한 양상 보임


Distributed Representations of Words and Phrases and their Compositionality (2013, Mikolov)
- word2vec 튜닝기법 추가된 버전
- 소스 공개
- 기존 skip-gram 공식에서의 softmax function 분모계산시간이 문제 --> 2가지 훈련방법 제시
1) Hierarchical Softmax
- word를 노드로 하는 bianry tree 구성 후, word로 진행하는 경로 각 노드에 대해 0 또는 1 label 부여해서 최적화
- 계산 시간 감소: |V| --> log|V|
* 문제: 별 관계없는 단어들끼리 같은 경로 공유시 같은 파라미터로 훈련되는 게 논리적으로 이상해 보임. 차라리 트리 구성시에 명사/형용사/동사 등으로 간단하게라도 클러스터링해서 묶으면 좀 더 나을 듯
2) Negative Sampling
- 현재 훈련하고자 하는 word와 그에 대한 context words가 있을 때, target word를 현재 context와 관계없는 임의의 word로 바꾸어 negative example들 k개 생성해서 훈련.
- 작은 훈련셋에서는 k = 5-20, 큰 훈련셋에서는 k = 2-5 가 적절하다고 함
- 대체적으로 NS가 HS보다 성능 높음
- 빈도 수에 따라 subsampling 수행
-- 많은 빈도수 단어에 대해 subsampling (a, the, in 등등)
* in 같은 단어는 중요할 수 있음
* 미리 사람이 뽑은 stopword 제거하는 방식이 더 좋을 수 있음
- 논문에 언급 없지만, context window를 c라고 했을 때 word2vec 코드에서 실제로 2c개의 context를 이용하지 않음; 실제로는 context window를 1-c 사이에서 랜덤으로 정해 훈련함
* 이렇게 하면 target word와 가까운 context word에 대한 훈련 빈도수가 상대적으로 커져서 word order를 고려해 주는 효과가 있음
* 하지만 임의로 context word를 빼기 때문에 target word와 거리가 멀지만 중요할 수 있는 context에 대해 훈련이 부족할 수 있음
- Phrase를 고려한 실험 추가
-- Vietnam + capital = Hanoi, Ho Chi Minh City 등
* word2vec 관련 참고링크:
http://alexminnaar.com/word2vec-tutorial-part-i-the-skip-gram-model.html
source: https://code.google.com/p/word2vec/source/browse/trunk/word2vec.c?spec=svn42&r=42#482
http://www.slideshare.net/lewuathe/drawing-word2vec
http://www.slideshare.net/ssuser9cc1bd/piji-li-dltm
한글: http://www.slideshare.net/JungkyuLee1/from-a-neural-probalistic-language-model-to-word2vec
[dependency-based context]
Dependency-Based Word Embeddings (2014, Levy and Goldberg)
- dependency parser를 이용해 context를 확장
 - 단순히 target word의 앞뒤 word가 아니라, 의존관계에 따라 앞뒤 context를 추출
- 단순히 target word의 앞뒤 word가 아니라, 의존관계에 따라 앞뒤 context를 추출
- 기존 방법 이용시 context window가 2라면, telescope는 discovers의 context에서 제외되고, Australian은 포함됨
- 실험 비교는 word2vec에서 cbow에만 수행함 (skip-gram 빠짐)

- WordSim353, Chiarello dataset을 이용해 related one을 찾는 실험에서 우위
* related one을 찾는 task에서만 우위, similar one과 다를 수 있음, analogy task에서는 성능에서 매우 열세라고 함
* 의존 파서를 이용한 context 활용은 충분히 고려할 만 하지만, 정확한 예상 효과, 부작용 등 파악해야 함 (task에 따라 최적의 context가 달라질 수 있음)
* context 선정 방법, objective function, 성능 비교 실험 등에서 추가 작업 여지 있음
Looking for Hyponyms in Vector Space (2014 CoNLL, Rei and Briscoe)
- hyponym: 하의어
- dependency-based vector space를 이용한 하의어 찾기
- target task - hyponym generation: 주어진 하나의 단어에 대해 하의어 리스트 출력
- 실험:
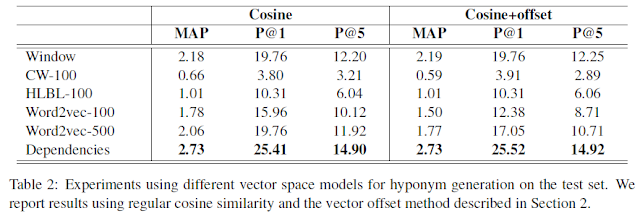 - dependency-based vector space가 topical하고 단어간 functional similarity를 고려하는 task에 대해 우위를 보임
- dependency-based vector space가 topical하고 단어간 functional similarity를 고려하는 task에 대해 우위를 보임
 - 상하의어 특성을 고려한 weighted cosine 이용시 가장 좋은 성능
- 상하의어 특성을 고려한 weighted cosine 이용시 가장 좋은 성능
- word2vec + dependency-based (Combined)에서 압도적 성능
-- word2vec: useful information about topic, semantics
-- dependency-based: grammatical roles and directional containment
-- 양측 방법에서 score 구한 뒤 geometric average 이용

A Neural Probabilistic Language Model (2003, Bengio)
- LM에 distributional representation을 적용한 대표 논문
- 계산복잡도 높음
Recurrent Neural Network based Language Model (2010, Mikolov)
Linguistic Regularities in Continuous Space Word Representations (2013, Mikolov)
- RNN을 이용한 LM
[word2vec]
Efficient Estimation of Word Representations in Vector Space (2013, Mikolov)
- word2vec 방법론 초기 논문
- 준수한 성능에 계산복잡도 감소
- CBOW, Skip-gram

-- hidden layer에서 non-linearity 제거
-- word간 projection layer 공유
- 대체적으로 semantic accuracy는 skip-gram이 낫고 syntactic accuracy는 cbow가 높은 것으로 보임
* 성능 수치 차이 및 전반적으로 봤을 때 skip-gram이 낫다고 보임 --> 이후 다른 논문들에서도 비슷한 양상 보임


Distributed Representations of Words and Phrases and their Compositionality (2013, Mikolov)
- word2vec 튜닝기법 추가된 버전
- 소스 공개
- 기존 skip-gram 공식에서의 softmax function 분모계산시간이 문제 --> 2가지 훈련방법 제시
1) Hierarchical Softmax
- word를 노드로 하는 bianry tree 구성 후, word로 진행하는 경로 각 노드에 대해 0 또는 1 label 부여해서 최적화
- 계산 시간 감소: |V| --> log|V|
* 문제: 별 관계없는 단어들끼리 같은 경로 공유시 같은 파라미터로 훈련되는 게 논리적으로 이상해 보임. 차라리 트리 구성시에 명사/형용사/동사 등으로 간단하게라도 클러스터링해서 묶으면 좀 더 나을 듯
2) Negative Sampling
- 현재 훈련하고자 하는 word와 그에 대한 context words가 있을 때, target word를 현재 context와 관계없는 임의의 word로 바꾸어 negative example들 k개 생성해서 훈련.
- 작은 훈련셋에서는 k = 5-20, 큰 훈련셋에서는 k = 2-5 가 적절하다고 함
- 대체적으로 NS가 HS보다 성능 높음
- 빈도 수에 따라 subsampling 수행
-- 많은 빈도수 단어에 대해 subsampling (a, the, in 등등)
* in 같은 단어는 중요할 수 있음
* 미리 사람이 뽑은 stopword 제거하는 방식이 더 좋을 수 있음
- 논문에 언급 없지만, context window를 c라고 했을 때 word2vec 코드에서 실제로 2c개의 context를 이용하지 않음; 실제로는 context window를 1-c 사이에서 랜덤으로 정해 훈련함
* 이렇게 하면 target word와 가까운 context word에 대한 훈련 빈도수가 상대적으로 커져서 word order를 고려해 주는 효과가 있음
* 하지만 임의로 context word를 빼기 때문에 target word와 거리가 멀지만 중요할 수 있는 context에 대해 훈련이 부족할 수 있음
- Phrase를 고려한 실험 추가
-- Vietnam + capital = Hanoi, Ho Chi Minh City 등
* word2vec 관련 참고링크:
http://alexminnaar.com/word2vec-tutorial-part-i-the-skip-gram-model.html
source: https://code.google.com/p/word2vec/source/browse/trunk/word2vec.c?spec=svn42&r=42#482
http://www.slideshare.net/lewuathe/drawing-word2vec
http://www.slideshare.net/ssuser9cc1bd/piji-li-dltm
한글: http://www.slideshare.net/JungkyuLee1/from-a-neural-probalistic-language-model-to-word2vec
[dependency-based context]
Dependency-Based Word Embeddings (2014, Levy and Goldberg)
- dependency parser를 이용해 context를 확장

- 기존 방법 이용시 context window가 2라면, telescope는 discovers의 context에서 제외되고, Australian은 포함됨
- 실험 비교는 word2vec에서 cbow에만 수행함 (skip-gram 빠짐)

- WordSim353, Chiarello dataset을 이용해 related one을 찾는 실험에서 우위
* related one을 찾는 task에서만 우위, similar one과 다를 수 있음, analogy task에서는 성능에서 매우 열세라고 함
* 의존 파서를 이용한 context 활용은 충분히 고려할 만 하지만, 정확한 예상 효과, 부작용 등 파악해야 함 (task에 따라 최적의 context가 달라질 수 있음)
* context 선정 방법, objective function, 성능 비교 실험 등에서 추가 작업 여지 있음
Looking for Hyponyms in Vector Space (2014 CoNLL, Rei and Briscoe)
- hyponym: 하의어
- dependency-based vector space를 이용한 하의어 찾기
- target task - hyponym generation: 주어진 하나의 단어에 대해 하의어 리스트 출력
- 실험:


- word2vec + dependency-based (Combined)에서 압도적 성능
-- word2vec: useful information about topic, semantics
-- dependency-based: grammatical roles and directional containment
-- 양측 방법에서 score 구한 뒤 geometric average 이용

피드 구독하기:
글 (Atom)